Материал: ГЛАВА 8_1
Если вернуться к затронутой выше взаимосвязи между линейной регрессией и корреляцией, то здесь мы можем сделать следующие дополнения. Пусть все точки-наблюдения аккуратно размещены на регрессионной прямой. Перед нами почти невероятный случай абсолютной линейной зависимости. Зная, например, что коэффициент b (нестандартизованный) равен 313, мы можем утверждать, что именно такова величина воздействия переменной X на зависимую переменную Y. Кроме того, мы можем точно сказать, что единичная прибавка в величине X вызовет увеличение Y на ту же величину, 313 (если, допустим, Х— стаж работы, а У — зарплата, то с увеличением стажа на год зарплата растет на 313 рублей). В этом случае коэффициент корреляции будет равен в точности 1,0, что свидетельствует о сильном, «абсолютном», характере связи переменных. Различие между предсказанными и наблюдаемыми значениями в этом случае отсутствует. Корреляция как мера точности прогноза показывает, что ошибок предсказания просто нет.
15 Более детальные сведения можно найти в статистической литературе. Очень доступно проблема излагается, в частности, в кн.: Гласе Дж., Стенли Дж. Указ. соч. С. 123—141. Для тех же, кто захочет осуществить «ручную» регрессию для какого-либо из использованных примеров, просто приведем формулы для вычисления нестандартизированных коэффициентов (обозначения те же, что и выше):
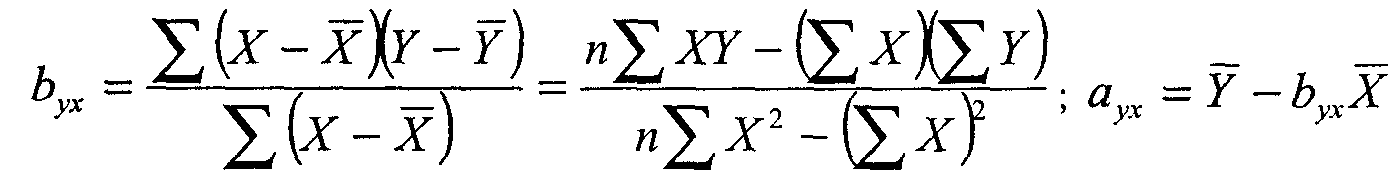
В действительности, однако, из-за влияния других переменных и случайной выборочной ошибки точки-наблюдения обычно лежат выше или ниже прямой, которая, как говорилось, является лишь наилучшим приближением реальных данных. Коэффициент корреляции Пирсона r и величина r2 по-прежнему служат оценкой точности прогноза, основанного на линии регрессии. Вполне возможны ситуации, когда коэффициент регрессии очень велик, воздействие X на Y просто громадно, но корреляция низка и, следовательно, точность прогноза невелика. Нет ничего необычного и в обратной ситуации: воздействие Х на Y относительно мало, а коэффициент корреляции и объясненная дисперсия очень велики. Посмотрев на приведенные выше диаграммы рассеивания, можно легко уяснить себе смысл отношения между корреляцией и регрессией: первая имеет прямое отношение к «разбросанности» точек наблюдения (чем выше «разбросанность», тем ниже r2 и ненадежнее прогноз), тогда как коэффициент регрессии описывает наклон, «крутизну» линии. Однако существующее здесь различие не стоит и преувеличивать: регрессионный коэффициент (наклон прямой) для стандартизованных данных в точности равен коэффициенту корреляции Пирсона r16. 16 Легко понять, что при измерении в единицах стандартного отклонения максимальная связь (Р= 1,0) соответствует ситуации, когда сдвигу от начала координат в 1 ед. стандартного отклонения по Х соответствует увеличение У также на 1 ед. стандартного отклонения. Важно заметить, что в случае стандартизированных переменных (и только в этом случае) коэффициенты регрессии Y no X и X noY будут совпадать.
Предположим, что исследователь изучает зависимость между образованием матери (X) и образованием детей (Y). Обе переменные измерены как количество лет, затраченных на получение образования. Найдя достаточно высокую корреляцию между Х и У— скажем, равную 0,71, — он также находит коэффициенты регрессии а и b и устанавливает, что r2 (называемый также коэффициентом детерминации) в данном случае приближенно равен 0,5. Это значит, что доля вариации в значениях переменной Y (образование детей), объясненная воздействием переменной-предиктора Х (материнское образование), составляет около 50% общей дисперсии предсказываемой переменной. Коэффициент корреляции между переменными достаточно велик и статистически значим даже для не очень большой выборки. Следовательно, обнаруженная взаимосвязь переменных не может быть объяснена случайными погрешностями выборки. В пользу предложенной исследователем причинной гипотезы говорит и то обстоятельство, что альтернативная гипотеза — образование детей влияет на образовательный статус родителей — крайне неправдоподобна и может быть отвергнута на основании содержательных представлений о временной упорядоченности событий. Однако все еще не исключены те возможности, которые мы обсуждали в параграфе, посвященном методу уточнения. Иными словами, нам следует считаться с вероятностью того, что какая-то другая переменная (или несколько переменных) определяют и образование родителей и образование детей (например, финансовые возможности либо интеллект). Чтобы проверить такую конкурирующую гипотезу, следует рассчитать так называемую частную корреляцию. Логика расчета частной корреляции совпадает с логикой построения частных таблиц сопряженности при использовании метода уточнения. Построить частные таблицы сопряженности для различных уровней контрольной переменной в случае, когда переменные измерены на интервальном уровне,— это практически неразрешимая задача.
Чтобы убедиться в этом, достаточно подсчитать, каким должно быть количество таблиц уже при десяти-двенадцати категориях каждой переменной. Расчет коэффициента частной корреляции— это простейшее средство уточнения исходной причинной модели при введении дополнительной переменной. Интерпретация коэффициента частной корреляции не отличается от интерпретации частных таблиц сопряженности: частной корреляцией называют корреляцию между двумя переменными, когда статистически контролируется, или «поддерживается на постоянном уровне», третья переменная (набор переменных).
Если, предположим, при изучении корреляции между образованием и доходом нам понадобится «вычесть» из полученной величины эффект интеллекта, предположительно влияющего и на образование, и на доход, достаточно воспользоваться процедурой вычисления частной корреляции. Полученная величина будет свидетельствовать о чистом влиянии образования на доход, из которого «вычтена» линейная зависимость образования от интеллекта.
Мюллер и соавторы 17 приводят интересный пример использования коэффициента частной корреляции. В исследовании П. Риттербэнда и Р. Силберстайна изучались студенческие беспорядки 1968—1969 гг. Одна из гипотез заключалась в том, что число нарушений дисциплины и демонстраций протеста в старших классах учебных заведений связано с различиями показателей академической успеваемости учащихся. Корреляция между частотой «политических» беспорядков и средней успеваемостью оказалась отрицательной (хуже успеваемость — больше беспорядков) и статистически значимой (r = -0,36). Однако еще более высокой была корреляция между частотой беспорядков и долей чернокожих учащихся (r=0,54). Исследователи решили проверить, сохранится ли связь между беспорядками и успеваемостью, если статистически проконтролировать влияние расового состава учащихся. Коэффициент частной корреляции частоты беспорядков и успеваемости при контроле расового состава учащихся оказался равным нулю. Исходная корреляция между беспорядками и успеваемостью в данном случае может быть описана причинной моделью «ложной взаимосвязи» (см. рис. 19): наблюдаемые значения этих двух переменных скор-релированы лишь потому, что обе они зависят от третьей переменной — доли чернокожих в общем количестве учащихся. Чернокожие студенты, как заметили исследователи, оказались восприимчивее к предложенным самыми активными «политиканами» образцам участия в политических беспорядках. Кроме того, их успеваемость, помимо всяких политических событий, была устойчиво ниже, чем средняя успеваемость белых.
Коэффициент частной корреляции между переменными Х и. Y при контроле дополнительной переменной Z (т. е. при поддержании Z «на постоянном уровне») обозначают как rxy.z. Для его вычисления достаточно знать, величины наблюдаемых попарных корреляций между переменными X, Y и Z (т. е. простых корреляций — rxy, ryz, rxz):
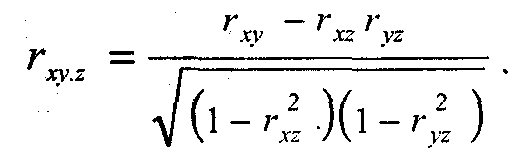
Как всякая выборочная статистика, коэффициент корреляции подвержен выборочному разбросу. Существует некоторая вероятность того, что для данной вы-
17 Mueller J., Schuessler К., Costner H. Statistical Reasoning in Sociology. 3rd ed. Boston:
Haighton Mifflin Co, 1977. P. 279—281.
борки будет получено ненулевое значение коэффициента корреляции, тогда как истинное его значение для генеральной совокупности равно нулю. Иными словами, существует задача оценки значимости полученных значений корреляций и коэффициентов регрессии, относящаяся к области теории статистического вывода. Описание соответствующих статистических методов выходит за рамки этой книги, поэтому мы рассмотрим лишь самые общие принципы, позволяющие решать описанную задачу в простых случаях и интерпретировать соответствующие показатели при использовании стандартных компьютерных программ.
Прежде всего вероятностная оценка коэффициента корреляции подразумевает оценку отношения к его случайной ошибке. Удобная, хотя и не вполне надежная формула для вычисления ошибки коэффициента корреляции (тr), выглядит так18:
![]()
Всегда полезно вычислить отношение полученной величины r к его ошибке (т. е. r/тi). В использовавшемся нами примере данных о погоде коэффициент корреляции оказался равен 0,91, а его выборочная ошибка составляет:
![]()
Отношение r к mr обозначаемое как t, составит (0,91/0,573)= 15,88. Разумеется, коэффициент, превосходящий свою случайную ошибку почти в 16 раз, может быть признан значимым даже без построения доверительных интервалов.
Когда значение г не столь близко к единице и выборка невелика, нужно все же проверить статистическую гипотезу о равенстве r нулю в генеральной совокупности. Для этого нужно определить t по формуле:
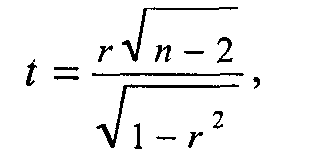
где t — это величина так называемого t-критерия Стьюдента (см. также главу 4), г — выборочный коэффициент корреляции, п — объем выборки. Для установления значимости вычисленной величины t-критерия пользуются таблицами t-распределения для (n - 2) степеней свободы (см. табл. 4.1). Во многих пособиях по статистике можно найти и готовые таблицы критических значений коэффициента корреляции r для данного уровня значимости а. В этом случае отпадает необходимость в каких-либо вычислениях t: достаточно сравнить полученную величину коэффициента корреляции с табличным значением 19. (Например, величина коэффициента корреляции r = 0,55 будет существенной на уровне значимости р = 0,01 даже для выборки объемом 105, так как критическое значение составляет 0,254.)
18 См.: Дружинин н. К. Логика оценки статистических гипотез. М.: Статистика, 1973. С. 112—114.
" См., в частности: Ликеш И., Ляга И. Основные таблицы математической статистики. М.: Финансы и статистика, 1985. (Табл. 14.)
Множественная регрессия и путевой анализ
Выше описывалась модель линейной регрессии для двух переменных. В действительности социолог довольно редко сталкивается со столь простыми моделями данных. Влияние одного фактора обычно может объяснить лишь часть разброса наблюдаемых значений независимой переменной. Метод частной корреляции позволяет нам проконтролировать эффекты воздействия любых других контрольных переменных, которые мы в состоянии измерить. (Стоит снова подчеркнуть здесь, что статистические методы изучения причинных взаимосвязей, в отличие от экспериментальных, позволяют нам контролировать лишь те источники вариации, которые мы способны концептуализировать и измерить.) Однако еще более интересной задачей является контроль одновременного воздействия нескольких независимых на одну зависимую переменную, а также сравнение эффекта воздействия разных независимых переменных и предсказание «отклика» независимой переменной. Именно эти задачи решают методы анализа, о которых пойдет речь в данном параграфе. Наше изложение будет неполным, так как более детальное обсуждение требует дополнительной математической подготовки. Мы будем ориентироваться на сравнительно скромные цели понимания общей логики и интерпретации результатов соответствующих статистических процедур.
Уравнение множественной регрессии — это определенная модель порождения данных. Важные допущения, принимаемые в этой модели, касаются уже известного вам требования линейности, а также аддитивности суммарного эффекта независимых переменных. Последнее означает, что воздействия разных независимых переменных просто суммируются, а не, скажем, перемножаются (мультипликативный эффект, в отличие от аддитивного, имеет место тогда, когда величина воздействия одной независимой переменной на зависимую, в свою очередь, находится под влиянием другой независимой переменной, т. е. независимые переменные взаимодействуют друг с другом).
Множественная регрессия во многом аналогична простой (бивариантной) регрессии. Отличие состоит в том, что регрессия осуществляется по двум и более независимым переменным одновременно, причем каждая из них входит в регрессионное уравнение с коэффициентом, позволяющим предсказать значения зависимой переменной с минимальным количеством ошибок (критерием здесь снова является метод наименьших квадратов). Частные коэффициенты в уравнении множественной регрессии показывают, какой будет величина воздействия соответствующей независимой переменной на зависимую при контроле влияния других независимых переменных. Если воспользоваться простейшей системой обозначений, то уравнение множественной регрессии для трех независимых переменных можно записать как:
![]()
где Y— это предсказываемое значение зависимой переменной, X1 ... Х3,— независимые переменные, а b, ... b3, — частные коэффициенты регрессии для каждой из зависимых переменных.
Коэффициенты b могут быть интерпретированы как показатели влияния каждой из независимых переменных на зависимую при контроле всех других независимых переменных в уравнении. В отличие от коэффициентов частной корреляции коэффициенты регрессии обладают размерностью. Они показывают,на сколько единиц изменится зависимая переменная при увеличении независимой на одну единицу (при контроле всех остальных переменных модели). Пусть, например, мы построили уравнение множественной регрессии, описывающее зависимость дохода от интеллекта (Х1) и стажа работы (Х2). Если величина b1 оказалась равной 100, это означает, что каждый дополнительный балл по шкале интеллекта увеличивает доход на 100 рублей. Значение b2= 950 говорит нам, что год стажа прибавляет 950 рублей. Однако «сырые» оценки интеллекта и стажа измерены в разных единицах. Для определения сравнительной значимости независимых переменных, входящих в уравнение множественной регрессии, мы должны подвергнуть все переменные стандартизации (т. е. перевести их в Z-оценки, см. выше). Стандартизованные коэффициенты множественной регрессии, которые удобнее всего обозначать как b* (либо греч. «бета» — B), меняются в пределах от -1,0 до +1,0. Они сохраняют свою величину при изменении масштаба шкалы: переход от измерения возраста в годах к измерению в днях не изменит соответствующий b*.
Стандартизованные коэффициенты позволяют оценить «вклад» каждой из переменных-предикторов в предсказание значений независимой переменной. Если в примере с влиянием интеллекта и стажа работы на доход окажется, что b1* = 0,25, a b2*=0,30, то можно заключить, что сравнительная значимость «веса» интеллекта и стажа в предсказании дохода различаются незначительно. Если же для одной переменной b1* =0,80, тогда как b2* =0,40, мы можем сказать, что эффект воздействия второй переменной в два раза меньше эффекта первой.
Чтобы определить ожидаемые значения зависимой переменной для отдельных индивидов, достаточно подставить в уравнение множественной регрессии соответствующие значения переменных-предикторов и вычисленных коэффициентов Ь. Пусть, например, мы хотим рассчитать прогнозное значение величины дохода для человека, чей коэффициент интеллекта равен 110, а стаж работы — 20 годам. Если b1, как в вышеприведенном примере, составляет 100, b2 = 950, а слагаемое а = 50000, то мы получим:
ожидаемый доход = 50000 +100 х 110 + 950 х 20 = 80000 руб.
Множественную регрессию можно использовать и для предсказания средних групповых значений, например среднего дохода мужчин-врачей. Единственное различие в данном случае заключается в использовании средних значений независимых переменных для подстановки в уравнение множественной регрессии. В качестве независимой переменной множественной регрессии могут использоваться и дихотомические переменные, которым приписывают значения 0 и 1 (например, пол). Для того чтобы включить в уравнение номинальную переменную с более чем двумя категориями, нужно создать соответствующее число новых, «фиктивных» переменных, каждая из которых будет кодироваться как О или 1 в зависимости от наличия или отсутствия категории-признака. Скажем, состоящую из трех категорий переменную «цвет глаз» можно представить с помощью трех переменных: Х1 — «голубые глаза», Х2 — «карие глаза», Х3, — «зеленые глаза». (Человек с голубыми глазами получит 1 по Х1 и 0 по двум другим переменным.)
Таблица 8.12 Множественный регрессионный анализ статистики изнасилований, 1979 г.21 |
|||
Независимая переменная |
Коэффициент b |
Коэффициент b* |
p< |
Индекс совокупного тиража порнографических журналов (SMCX) |
6,99 |
0,52 |
0,001 |
Показатель числа убийств и непредумышленных убийств |
1,70 |
0,55 |
0,001 |
Показатель числа публичных оскорблений с угрозой применения физической силы |
0,04 |
0,32 |
0,001 |
Индекс положения женщин (SWX) |
0,43 |
0,27 |
0,014 |
Число грабежей |
-0,03 |
-0,25 |
0,052 |
Процент черного населения |
-0,41 |
-0,38 |
0,001 |
Процент живущих ниже федерального уровня бедности |
1,11 |
0,29 |
0,011 |