Материал: Двоичная система счисления
Бит - это минимальная единица измерения информации (0 mini). За битом следует байт, состоящий из восьми бит, затем килобайт (кбайт) - 1024 байта, мегабайт (мбайт) - 1024 кбайта, гигобайт (гбайт) - 1024мбайт.
В компьютере для представления информации используется двоичное кодирование, так как удалось создать надежные работающие технические устройства, которые могут со стопроцентной надежностью сохранять и распознавать не более двух различных состояний (цифр). Все виды информации в компьютере кодируются на машинном языке, в виде логических последовательностей нулей и единиц.
Целые числа в компьютере хранятся в ячейках памяти, в этом случае каждому разряду ячейки памяти соответствует всегда один и тот же разряд числа.
Для хранения целых неотрицательных чисел отводится одна ячейка памяти, состоящая из восьми бит.
Например, число 1910 будет выглядеть:
|
0 |
0 |
0 |
1 |
0 |
0 |
1 |
1 |
Для хранения целых чисел со знаком (отрицательных) отводиться две ячейки памяти (16 битов), причем старший (левый) разряд отводиться под знак числа (если число положительное, то в знаковый разряд записывается 0, если отрицательное - 1).
Например, число -9810 будет выглядеть:
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
Начиная с конца 60-х годов, компьютеры все больше использовать для обработки текстовой информации и в настоящее время большая часть компьютеров в мире занято именно обработкой текстовой информации.
Традиционно для кодирования одного символа используется количество
информации равное 1 байту, то есть 8 бит. Если рассматривать символы как
возможные события, то получаем, что количество различных символов, которые
можно закодировать, будет равно 256. Такое количество символов вполне
достаточно для представления текстовой информации, включая прописные и строчные
буквы русского и латинского алфавитов, а так же цифры, знаки препинания и
математических операций, графические символы и так далее. Но способов
построения таких кодов очень много, рассмотрим один из них:
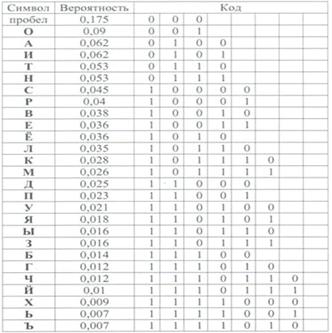
Алфавитное неравномерное двоичное кодирование
При алфавитном способе двоичного кодирования символы некоторого первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться. Оптимизировать кодирование можно за счет суммарной длительности сообщения. Суммарная длительность сообщения будет меньше, если применить следующий подход: чем буква первичного алфавита, встречается чаще, то присваиваем ей более короткой по длине код. Следовательно, коды букв, вероятность появления которых в сообщении выше, следует строить из возможно меньшего числа элементарных сигналов.
Возможны различные варианты двоичного кодирования, при этом важно, чтобы закодированное сообщение могло быть однозначно декодировано, т.е. чтобы в последовательности 0 и 1, которая представляет собой многобуквенное кодированное сообщение, всегда можно было бы различить обозначения отдельных букв.
Рассмотрим пример построения двоичного кода для символов русского
алфавита:
Заключение
В данной работе мы
) рассмотрели понятие систем счисления, выделили их виды,
) рассмотрели двоичную систему счисления;
) выделили применения двоичной системы счисления в жизни человека.
Двоичная система счисления удобна в использовании, что доказывают
разнообразные сферы ее применения. В данной работе рассмотрены не все сферы
применения двоичной системы счисления и работа в данной области может быть
продолжена.
Список используемой литературы
. Занимательные материалы по математике. 7 - 8 классы. / Составитель Галаева Е.А. - Волгоград: Издательско-торговый дом «Корифей», 2006. - 80 с.
. Раздел информатика, 2001 - 2007. Теле - школа. Интернет - школа «Просвещение.ru»
. Биографический словарь деятелей в области математики. / Бородин А.И., Бугай А.С. - Киев: «Радянська школа», 1979.
. Системы счисления. - 5-е издание. / Фомин С.В. - Москва: «Наука». Главная редакция физико-математической литературы, 1987. - 48 с. - (Популярные лекции по математике).
6. Сайт <http://numeration.ru/bin.html>