Материал: билеты теория информации
вспомогательных символов
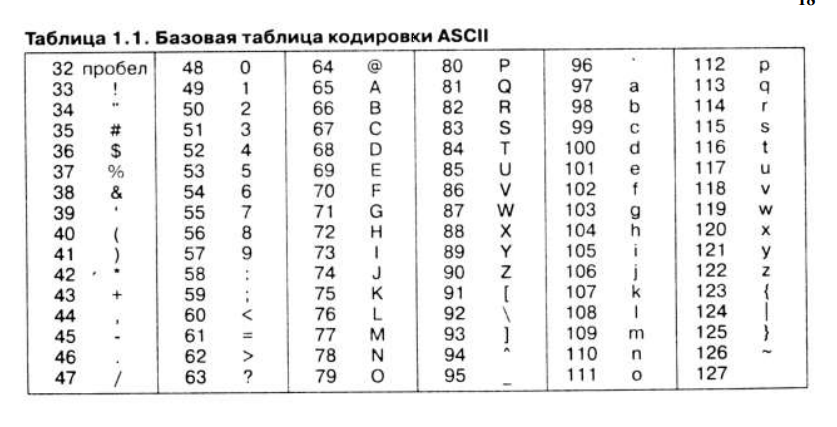
Впоследствии оказалось удобнее использовать 8-битовые кодировки (кодовые страницы), в которых нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. Таким образом, верхняя половина таблицы ASCII (до повсеместного внедрения Юникода) активно использовалась для представления локализированных символов, букв местного языка. Отсутствие единого стандарта размещения кириллических символов в таблице ASCII доставляло множество проблем с кодировками (КОИ-8, Windows-1251 и др.). Носители других языков с нелатинской письменностью тоже страдали, из-за наличия нескольких разных кодировок.
2) ISO-646
Стандарт ISO 646 (ECMA-6) предусматривает возможность размещения в ASCII национальных символов. Для этого предлагается заменять символы «@», «[», «\», «]», «^», «`», «{», «|», «}», «~». Также на месте знака решётки «#» может быть размещён символ фунта «£», а на месте символа доллара «$» — знак валюты «¤». Такая система хорошо подходит для европейских языков, так как в них используются символы латинского алфавита и лишь несколько дополнительных символов. Вариант ASCII, не содержащий национальных символов, называется «US-ASCII» или «international reference version».
-----Самым популярным из стандартов кодирования символов, в настоящий момент является стандарт ISO 646, созданный международной организацией стандартизации ISO, а точнее его первые 128 символов, которые кодировались при помощи 8 битов, но при этом первый бит всегда равнялся нулю. Ему было присвоено имя ASCII и иногда его еще называют 7-битовым стандартом. Он используется большинством компьютерных машин для написания символов латинского алфавита, а также для синтаксиса всех языков программирования и разметки, а также для всех типов данных.
Для поддержки языков, использующих в своем алфавите символы отличные от латинских, был использован восьмой бит байта, а это дало возможность добавить еще 128 дополнительных символов. Была создана серия кодировок ISO 8859, в которых первая часть - это 128 символов ASCII. Самая первая из них, ISO 8859-1, еще ее называют ISO Latin-1 или 8-битовой ASCII, содержит в себе практически все европейские нестандартные символы, а кодировка ISO 8859-5 является русской.
В свою очередь, организация Unicode Consortium создала на основе 16-битового кодирования одноименную кодировку, в которую решено было вместить 65536 символов, каждый весом в два байта. Первые 256 символов Unicode в точности соответствуют ISO 8859-1, а саму кодировку компьютерное сообщество признало и использует все чаще, и если основной кодировкой в HTML раньше считалась ISO 8859-1, то с появлением HTML 4.0, основной кодировкой стала Unicode.
Не желая останавливаться на достигнутом, ISO разработала новый, 32-битовый стандарт кодирования ISO 10646. Он совместим с Unicode, а также имеет несколько своих производных фоматов, одна из которых - формат UTF-8 внедрен в Windows.
3) ISO-2022
Многие языки или семейства языков, не основанные на латинском алфавите, такие как греческий, кириллический, арабский или иврит, исторически были представлены на компьютерах с различными 8-битными расширенными кодировками ASCII. Письменные восточноазиатские языки, в частности китайский, японский и корейский, используют гораздо больше символов, чем можно представить в 8-битном компьютерном байте, и впервые были представлены на компьютерах с двухбайтовыми кодировками для конкретного языка.
ISO/IEC 2022 был разработан как метод для решения обеих этих проблем: для представления символов в нескольких наборах символов в рамках одной кодировки символов и для представления больших наборов символов.
Вторым требованием ISO-2022 было то, что он должен быть совместим с 7-битными каналами связи. Таким образом, даже несмотря на то, что ISO-2022 является 8-битным набором символов, любая 8-битная последовательность может быть перекодирована для использования только 7-битных данных без потерь и, как правило, только небольшого увеличения размера.
Определения ISO-2022 наборов символов ISO-8859-X представляют собой конкретные фиксированные комбинации компонентов, которые образуют ISO-2022.
----(В начале 1970х годов использовалось сразу несколько кодировок, которые действительно были весьма различны, и рано или поздно приходилось переходить из одной кодировки в другую в середине многоязычного документа. Как же можно было отметить изменение кодировки?
Именно в это время появился стандарт ISO 2022 (1973 г.), последняя ревизия которого относится к 1994 году. Это не кодирование в полном смысле слова, а определенное количество управляющих последовательностей, дающих возможность применять до четырех кодировок в рамках одного и того же набора данных.
Согласно стандарту ISO 2022, были введены понятия «управляющий символ» и «графический символ», например CR, LF и ESC — это управляющие символы. Соответственно всё пространство из 28 =
= 256 символов разбивается на четыре части (табл. 7):
C0 (Control Left) — 0x000x1F;
GL (Graphic Left) — 0x200x7F;
C1 (Control Rigth) — 0x800x9F;
GR (Graphic Right) — 0xA00xFF.
Таким образом, под отображаемые символы (Graphic) отводится только 2562х32 = 192 позиции, 96 GL и 96 GR (иногда 94, без первой и последней позиций).
Одной из функций управляющих символов является переключение наборов символов в GR и GL. То есть всё происходит внутри 8битного пространства. Для этого применяются управляющие ESCпоследовательности, «старший» ESC — CSI и коды SI (Shift In) и SO (Shift Out). Так, КОИ7 сделан в точном соответствии со стандартом ISO2022 путем переключения GL кодами SI и SO.)
4)FIELDATA
Во второй половине 50х годов прошлого столетия для армии США с целью организации связи был разработан семибитный код, известный как FIELDATA (табл. 3). Он не был совместим ни с чем и ни в чем. Символы в нем произвольным образом перемешаны с управляющими командами, причем сами команды явно избыточны: например, наряду с полным набором прописных и строчных букв присутствуют команды переключения Upper Case/Lower Case. Код включал не только кодировку, но и спецификации электрических параметров, разьемов и пр. Он был предназначен для аппаратного кодирования/декодирования и использовался, например, в компьютерах Univac и Unisys.

MS расшифровывается как master space, UC/LC — смена кодов прописных и строчных букв, STOP, SPEC и IDLE обозначают «стоп», «специальное» и «неиспользуемый». В этой кодировке мы уже можем найти коды символов, которые несколько лет спустя будут применяться в ASCII. Код FIELDATA сохранился до нашего времени в старом ПО, написанном на Коболе (COBOL), для которого первоначально был выбран именно этот стандарт представления символов.
8-BIT СИМВОЛЬНЫЕ КОДИРОВКИ.
1) Code Pages
Кодовая страница (англ. code page) — таблица, сопоставляющая каждому значению байта некоторый символ (или его отсутствие). Обычно код символа имеет размер 8 бит, так что кодовая страница может содержать максимум 256 символов, из чего вытекает резкая недостаточность всякой 8-битной кодовой страницы для представления многоязычных текстов. К тому же часть символов используется как управляющие, из-за чего число печатных символов редко превышает 223[1].
Исторически термин code page был введён корпорацией IBM; сменные кодовые страницы использовались для поддержки различных языков (имеющих алфавитные системы письма). В последнее время имеется путаница между термином «кодовая страница» и более общим понятием набора символов (кодировки).
2) ISO/ EC 8859
Международные стандарты серии ISO-8859-x (например ISO-8859-1 : Latin1) сконструированы с учетом требований ISO-2022.
Была создана серия кодировок ISO 8859, в которых первая часть - это 128 символов ASCII. Самая первая из них, ISO 8859-1, еще ее называют ISO Latin-1 или 8-битовой ASCII, содержит в себе практически все европейские нестандартные символы, а кодировка ISO 8859-5 является русской.
Часть 1 (ISO 8859-1): Основана на ASCII, но дополнена для охвата большинства западноевропейских языков (Latin-1 Western European).
Часть 2 (ISO 8859-2): По сути то же самое, но переделана была для поддержки центрально- и восточноевропейских языков (Latin-2 Central European).
Часть 3 (ISO 8859-3): Поддержка южноевропейских языков (Latin-3 South European).
Часть 3 (ISO 8859-3): Аналогично для северной европы (Latin-4 North European).
3) EBCDIC
Хотя IBM принимала участие в разработке ASCII1963, в 1964 году она выпустила новую линию компьютеров — IBM System/360, для которых вплоть до начала 80х годов использовался другой код — EBCDIC, весьма громоздко устроенный и ведущий свое начало от перфокарт (табл. 5). С ним подавляющему большинству пользователей столкнуться вряд ли случится.
В 1801 году парижский ткач ЖозефМари Жаккард придумал прообраз перфокарт для работы на автоматических ткацких станках (машина Жаккарда).
Семьдесят девять лет спустя по другую сторону Атлантики, в Соединенных Штатах, крайне неудачно была проведена перепись населения. Неудачность ее состояла в том, что она заняла 7 лет (!), и большая часть этого времени была потрачена на обработку данных. Столкнувшись с такой проблемой, Бюро переписи населения организовало конкурс, чтобы найти изобретения, которые помогли бы решить ее. Конкурс выиграл Герман Холлерит, представивший прообраз компьютера, работающего с перфокартами, — электрическую табулирующую систему (Hollerith Electric Tabulating System).

Стандартная перфокарта
Холлерит организовал фирму по производству табуляционных машин TMC (Tabulating Machine Company), и стал продавать их железнодорожным управлениям и правительственным учреждениям (партия табуляторов была закуплена и Российской империей). Этому предприятию сопутствовал успех. С годами оно претерпело ряд изменений — слияний и переименований. С 1924 года фирма Холлерита стала называться IBM (International Business Machines).
Но какое отношение Холлерит имеет к EBCDIC? Посмотрите на рисунок. На нем показана стандартная перфокарта. Обратите внимание, что перфокарта имеет двенадцать строк, две из которых перфорируются, но не обозначены (их называют Х и Y), а оставшиеся десять несут цифровые обозначения от 0 до 9. Холлерит изобрел систему, с помощью которой можно закодировать буквы и цифры, не используя более двух отверстий на колонку. Система так и называется — код Холлерита (табл. 6).
Таблица 6
Отметка |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
На оси X |
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
На оси Y |
|
J |
K |
L |
M |
N |
O |
P |
Q |
R |
На нулевой |
|
|
S |
T |
U |
V |
W |
X |
Y |
Z |
Цифры |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Иными словами, чтобы получить А, пробиваются отверстия в колонке на строке X и на строке 1; чтобы получить S — в строке 2 и в строке 0 и т.д. На приведенной в примере перфокарте это можно легко проверить — закодированные слова продублированы на карте вверху обычным печатным способом.
Таким образом, код Холлерита был использован для кодирования перфокарт, то есть как код EBCDIC.
Несмотря на очевидные недостатки, IBM распространила этот код повсюду — было создано 57 национальных версий EBCDIC.
СТРУКТУРА И ПРИНЦИПЫ ОРГАНИЗАЦИИ UNICOD.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной —
UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для
65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее).
Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определенному стандартному виду.
В стандарте Юникода определены четыре формы нормализации текста:
форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных в соответствии с таблицами декомпозиции;
форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу в соответствии со следующими правилами:
- символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода, - в любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какойлибо символ B, который или является начальным, или имеет одинаковый либо больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию, - первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений); - символ X может быть первично совмещен с символом Y, если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>, - если очередной символ C не блокируется последним встреченным начальным базовым символом L и может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется;
форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке;
форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией.