Материал: Анализ эффективности функционального программирования на языке F# для многоядерных процессоров
Ведущие изготовители микроэлектронных компонентов, пытаясь сохранить тенденцию роста производительности, предлагают радикальные изменения в базовой архитектуре персональных компьютеров - многоядерные процессоры. Эти архитектурные изменения предполагают коррекцию подходов к созданию программ, а именно - активное использование физического параллелизма. Однако он, с одной стороны, неприменим к большому классу существующих последовательных алгоритмов, а с другой, означает возврат к низкоуровневому программированию со всеми вытекающими отсюда последствиями (от повышения квалификационных требований к разработчикам до увеличения затрат на создание и реинжиниринг программ) [18].
К моменту появления многоядерных процессоров уже существовали такие технологии как OpenMP (Open Multi-Processing) и MPI(Message Passing Interface) для многопроцессорных систем. Обе они могут применяться для написания программ для многоядерных процессоров. Сравним эти технологии.
Достоинства OpenMP:
На OpenMP программы легче писать и отлаживать чем на MPI
Поэтапное распараллеливание - директивы могут постепенно добавляться в программу
Программы могут выполняться также последовательно
Для того чтобы сделать программу параллельной обычно не требуется никаких изменения последовательно кода.
Программы просты для понимания, облегчена их поддержка
Недостатки OpenMP:
Программы могут быть исполнены лишь на многопроцессорных или многоядерных системах с общей памятью.
Необходим компилятор поддерживающий openMP.
В основном можно использовать только для распараллеливания циклов.
Достоинства MPI:
Программы могут выполняться на многопроцессорных системах как с распределенной так и с общей памятью.
Каждый процесс имеет свои локальные переменные.
Покрывает больший спектр задач чем openMP.
Недостатки MPI:
Требуется вносить достаточно много изменений для перехода от последовательной программы к параллельной.
Трудно отлаживать.
Производительность ограничена связями между вычислительными узлами [19].
Обе этих технологии имеют довольно значительные недостатки, которые осложняют широкое их распространение в программирование для многоядерных процессоров.
Разработки компании Microsoft избавляют программиста от необходимости управления потоками и взаимоблокировками на низком уровне. Visual Studio 2010 и .NET Framework 4 улучают поддержку параллельного программирования, путем предоставления новой среды выполнения, новых типов библиотек класса и новых средств диагностики. Эти функциональные возможности упрощают параллельную разработку, что позволяет разработчикам писать эффективный, детализированный и масштабируемый параллельный код с помощью естественных выразительных средств без необходимости непосредственной работы с потоками или пулом потоков [20].
Параллельная модель программирования в .NET 4.0 включает две возможности:(Task Parallel Library) - улучшенное средство для работы с потоками - программист работает не с потоками а с задачами. Содержит два главных класса: Task и Parallel. Класс Parallel в частности библиотека содержит параллельные реализация таких конструкций как For, Foreach, Invoke.(Parallel Language-Integrated Query) - известная библиотеки LINQ с возможностью параллельного исполнения запросов [21].
Язык F# может использовать эти возможности .NET для написания параллельных программ, но в его активе имеются и свои инструменты для этих целей.
Асинхронные потоки операций - один из самых интересных примеров практического использования вычислительных выражений. Код, выполняющий какие либо неблокирующие операции ввода-вывода, как правило сложен для понимания, поскольку представляет из себя множество callback-методов, каждый из которых обрабатывает какой-то промежуточный результат и возможно начинает новую асинхронную операцию. Асинхронные потоки операций позволяют писать асинхронный код последовательно, не определяя callback-методы явно. Для создания асинхронного потока операций используется блок async:
System.IO
open System.NetMicrosoft.FSharp.Control.WebExtensionsgetPage (url:string) ={req = WebRequest.Create(url)! res = req.AsyncGetResponse()stream = res.GetResponseStream()reader = new StreamReader(stream)! result = reader.AsyncReadToEnd()result
}
Построитель асинхронного потока операций,
работает следующим образом. Встретив оператор let! или do!, он начинает
выполнять операцию асинхронно, при этом метод, начинающий асинхронную операцию,
получит оставшуюся часть блока async в качестве функции обратного вызова. После
завершения асинхронной операции переданный callback продолжит выполнение
асинхронного потока операций, но, возможно, уже в другом потоке операционной
системы (для выполнения кода используется пул потоков). В результате код
выглядит так, как будто он выполняется последовательно. То, что может быть с
легкостью записано внутри блока async с использованием циклов и условных
операторов, достаточно сложно реализуется с использованием обычной техники,
требующей описания множества callback-методов и передачей состояния между их
вызовами.- это класс из стандартной библиотеки F#, реализующий один из
паттернов параллельного программирования. MailboxProcessor является агентом,
обрабатывающим очередь сообщений, которые поставляются ему извне при помощи
метода Post. Вся конкурентность поддерживается реализацией класса, который
содержит очередь с возможностью одновременной записи несколькими писателями и
чтения одним единственным читателем, которым является сам агент [17].
let agent = MailboxProcessor.Start(fun inbox ->{true do! msg = inbox.Receive()"message received: '%s'" msg
})
2.2 Анализ эффективности
программирования на F# для многоядерных процессоров
Для исследования эффективности программирования на языке F# была выбрана одна из базовых операций работы процессора - умножение матриц для чисел с плавающей точкой. Одним из критериев является тот, что умножение матриц легко поддается распараллеливанию. Были выбраны алгоритмы эффективного умножения, которые также способствуют написанию параллельной программы. Для сравнения, аналогичные программы были написаны на императивных языках С++ и C#.
Существует множество алгоритмов перемножения матриц: алгоритм Штрассена, алгоритм Пана, алгоритм Бини, алгоритмы Шёнхаге, алгоритм Копперсмита-Винограда, алгоритмы с использованием теории групп.
Данные алгоритмы предусматривают оптимизацию по способу умножения, но существуют также алгоритмы, оптимизирующие доступ к памяти и позволяющие лучше распараллеливать задачу. Среди таких алгоритмов можно выделить:
ленточный алгоритм;
алгоритм Фокса;
алгоритм Кэннона;преобразование (Morton-order);
В программе для анализа эффективности параллельного программирования использовались алгоритмы Штрассена и Z-преобразования матриц. Рассмотрим их подробней.
Пусть A, B - две квадратные матрицы над кольцом
R. Матрица C получается по формуле:
![]()
Если размер умножаемых матриц n не является натуральной степенью двойки, мы дополняем исходные матрицы дополнительными нулевыми строками и столбцами. При этом мы получаем удобные для рекурсивного умножения размеры, но теряем в эффективности за счёт дополнительных ненужных умножений.
Разделим матрицы A, B и C на равные по размеру
блочные матрицы
![]()
где
![]()
![]()
Однако с помощью этой процедуры нам не удалось уменьшить количество умножений. Как и в обычном методе, нам требуется 8 умножений.
Теперь определим новые матрицы
![]()
![]()
![]()
![]()
![]()
![]()
![]()
которые затем используются для выражения Ci,j.
Таким образом, нам нужно всего 7 умножений на каждом этапе рекурсии. Элементы
матрицы C выражаются из Pk по формулам
![]()
![]()
![]()
![]()
Итерационный процесс продолжается n раз, до тех
пор пока матрицы Ci,j не выродятся в числа (элементы кольца R). На практике
итерации останавливают при размере матриц от 32 до 128 и далее используют
обычный метод умножения матриц. Это делают из-за того, что алгоритм Штрассена
теряет эффективность по сравнению с обычным на малых матрицах из-за
дополнительных копирований массивов [22].преобразование, или код Мортона
(рис.1) впервые был предложен в 1966 году Г.М. Мортоном, он представляет собой
пространственную кривую, часто использующуюся в информатике. Благодаря сохраняющему
локальность поведению он используется в структурах данных для перевода
многомерной информации в одно измерение. Z-значение точки легко вычисляется с
помощью бинарного представления значений координат. Как только данные
отсортированы в этом порядке, к ним может быть применена любая одномерная
структура, например деревья двоичного поиска, B-деревья, списки или
хэш-таблицы.

Рис. 1 - Графическое представление
Z-преобразования
Для исследования были написаны программы, реализующие умножение матриц на языках С++ и С# с использованием OpenMP и Parallel Extensions, а также на языке F# с использованием асинхронных выражений. Исследование проводилось на двухъядерном процессоре Inter Core 2 Duo, 2.4 Ghz, 3Mb Cache, 3Gb оперативной памяти, среда Visual Studio 2008 Team System, операционная система Microsoft Windows Vista Home Edition, библиотека для параллельных вычислений ParallelExtensions_Jun08CTP, сборка F# 1.9.6.16.
Для исследования были реализованы следующие алгоритмы умножения матриц:
Классический (![]() ).
).
Классический с использованием Z-преобразования.
Штрассена с использованием Z-преобразования.
Результаты измерения времени работы этих
алгоритмов для выбранных языков программирования представлены на рисунках 2-6.
На рисунке 7 для сравнения был добавлен график зависимости времени выполнения
программы от размера матриц для встроенного метода умножения матриц библиотеки
Math платформы .NET.
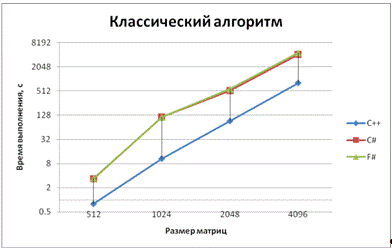
Рис. 2 - График зависимости времени выполнения
от размера матриц для классического алгоритма умножения
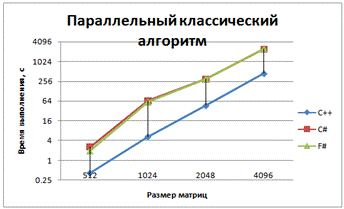
Рис. 3 - График зависимости времени выполнения
от размера матриц для параллельной версии классического алгоритма умножения
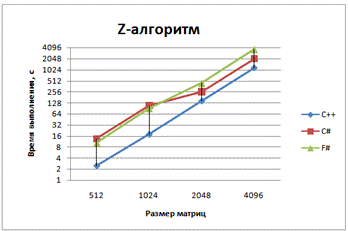
Рис. 4 - График зависимости времени выполнения
от размера матриц для классического алгоритма умножения с использованием
Z-преобразования матриц
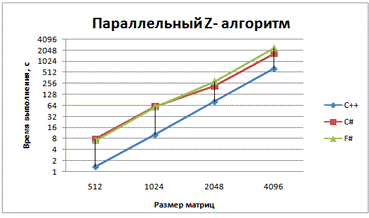
Рис. 5 - График зависимости времени выполнения
от размера матриц для параллельной версии классического алгоритма умножения с
использованием Z-преобразования матриц
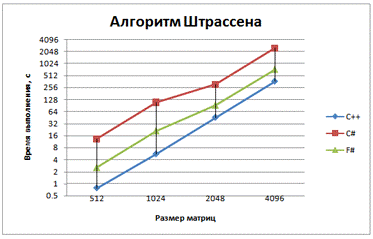
Рис. 6 - График зависимости времени выполнения
от размера матриц для алгоритма Штрассена с использованием Z-преобразования
матриц
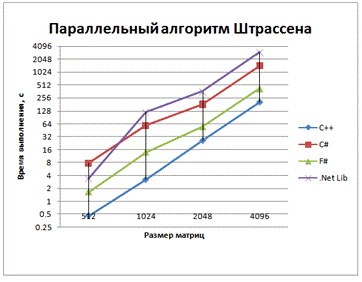
Рис. 7 - График зависимости времени выполнения
от размера матриц для параллельной версии алгоритма Штрассена с использованием
Z-преобразования матриц
После проведенного эксперимента проанализируем полученные результаты:
При обычном и обычном параллельном умножениях .NET языки показали одинаковую производительность, чего и следовало ожидать. Здесь и далее С++ намного опережает их по производительности, что доказывает целесообразность использования для приложений, требующих высокой скорости вычислений компилируемых языков, а F# и C# - интерпретируемые языки. .NET совместимые языки компилируются во второй, кроссплатформенный язык, который называется CIL (Common Intermediate Language). А уже зависимая от платформы среда CLR (Common Language Runtime) компилирует CIL в машинный код, который может быть выполнен на данной платформе.
Умножение с использованием Z-преобразования матриц лучше проходит на С#, чем на F#, но значительно хуже распараллеливается (всего 20-25%).
Массивы располагаются линейно в оперативной памяти, благодаря Z-преобразованию доступ к ним осуществляется последовательно, ниже процент cache-misses, это приводит к уменьшению времени выполнения умножений.
Использование метода Штрассена, как и ожидалось, привело к ускорению работы программы.
В умножении с использованием метода Штрассена F# показывает лучшие результаты, чем C#. Следует полагать, что это происходит благодаря отходу от императивного способа создания новых матриц и использования связывания имен let.
На основе полученных результатов можно сделать
вывод, что язык F# позволяет эффективно распараллеливать и решать такую
стандартную задачу как умножение матриц, обходя при этом по эффективности
другой язык работающий на платформе .NET - C#, но уступая языку С++,
работающему с неуправляемой памятью.
3. АНАЛИЗ ЭФФЕКТИВНОСТИ ФУНКЦИОНАЛЬНОГО ПРОГРАММИРОВАНИЯ НА ЯЗЫКЕ F# ДЛЯ РЕШЕНИЯ ЗАДАЧИ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ДЛЯ МНОГОЯДЕРНЫХ ПРОЦЕССОРОВ
.1 Описание задачи
Задача умножения матриц является достаточно абстрактной и не привязана к конкретной проблеме из реального мира, а для исследования эффективности определенного языка необходимо учитывать возможность его применения на практике. В связи с этим для исследования нужно было найти задачу, обладающую следующими свойствами:
Актуальность. Для того чтобы определить язык как эффективный, необходимо убедиться, что он может решать актуальные задачи и получать убедительные результаты.
Реализуемость. Для анализа языка задача не должна быть слишком сложной, но она должна охватывать базовые требования, которые должны обязательно реализовываться в современном языке.
Возможность распараллеливания. Поскольку анализ языка проводится в частности для многоядерных процессоров, нужно убедиться в том, что язык позволяет эффективно распределять нагрузку на данный тип вычислительных систем.
Наглядность. Хорошей практикой для описания новых языков является реализация наглядных примеров, так как это способствует восприятию его как альтернативы существующим языкам.
В архиве Microsoft был найден набор таких примеров от 2009-12-09. Описание примеров можно найти в источнике [22]. Из этих примеров для исследования была выбрана задача построения и обработки классического множества Мандельброта.
В математике множество Мандельброта - это
фрактал, определённый как множество точек С на комплексной плоскости, для
которых итеративная последовательность
![]()
![]()
не уходит на бесконечность.
Впервые множество Мандельброта было описано в
1905 году Пьером Фату (Pierre Fatou), французским математиком, работавшим в
области аналитической динамики комплексных чисел. Фату изучал рекурсивные
процессы вида ![]()