Материал: 1_2_3_ДХафф
Эта страница «сцепляется» с 1.1
1.2. Код ФаноШеннона
В методе, предложенном
Р. Фано
(R. M. Fano)
и К. Шенноном
(C. E. Shannon),
префиксный код (и соответственно –
кодовое дерево) строится следующим
образом («сверху вниз»). Пусть набор
(wi)1n
– упорядочен, а именно: w1 w2 … wn 1 wn.
В качестве корня дерева выбирается
такой узел (и соответственно набор
(wi)1n
разбивается на 2 поднабора
![]() и
и
![]() так), что веса поддеревьев различаются
минимально, т. е. если k =
так), что веса поддеревьев различаются
минимально, т. е. если k = ![]() ,
то коды сообщений
,
то коды сообщений
![]() оказываются в левом поддереве, а коды
сообщений
оказываются в левом поддереве, а коды
сообщений
![]()
в правом поддереве. Эта процедура
повторяется для поддеревьев до тех пор,
пока не будет получен лист в качестве
текущего поддерева.
в правом поддереве. Эта процедура
повторяется для поддеревьев до тех пор,
пока не будет получен лист в качестве
текущего поддерева.
Пример построения кода ФаноШеннона. Пусть n = 5, m = 20 и
|
wi |
8 |
3 |
3 |
3 |
3 |
|
i |
А |
Б |
В |
Г |
Д |
Т
20(АБВГД)
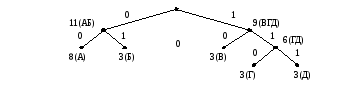
Здесь каждому узлу дерева приписаны символ или группа символов и их веса. Кодовые слова даны в таблице
|
wi |
8 |
3 |
3 |
3 |
3 |
|
i |
А |
Б |
В |
Г |
Д |
|
ci |
00 |
01 |
10 |
110 |
111 |
Полная длина кода есть L = 2(8 + 3 + 3) + 3(3 + 3) = 46 бит. Равномерный код (по 3 бита) дал бы суммарную длину L = 320 = 60 бит.
Отметим, что левые и правые поддеревья в кодовом дереве можно менять местами. При этом код будет изменяться, но значение L не изменится. Для определенности удобно, например, с целью облегчения проверки выполнения заданий, левым поддеревом выбирать поддерево с меньшим весом. Тогда в последнем примере будем иметь результирующее дерево следующего вида
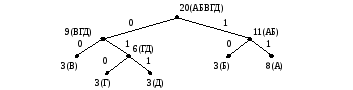
Оказывается, что
для рассмотренного примера можно найти
более экономный (в смысле значения L)
код. Действительно, следующее кодовое
дерево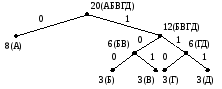
порождает код
|
wi |
8 |
3 |
3 |
3 |
3 |
|
i |
А |
Б |
В |
Г |
Д |
|
ci |
0 |
100 |
101 |
110 |
111 |
Для этого кода имеем L = 81+ 3(3 + 3 + 3 + 3) = 44 бита, что меньше, чем дает код ФаноШеннона. Этот пример показывает, что код ФаноШеннона не является оптимальным кодом.
1.3. Задача оптимального кодирования
Итак, задача построения оптимального префиксного кода есть задача минимизации функции L = i=1..n wi li целочисленных положительных переменных (li)1n при заданном наборе (wi)1n и при условии (пока не формализованном) выполнения свойства префиксности кода. Набор переменных (li)1n, минимизирующий L, определяет структуру дерева (кода).
Интересно, что аналогичным образом формулируются и некоторые, казалось бы, совершенно другие задачи.
Задача поиска (тестирования). Производится поиск на основе последовательных сравнений (решений) или последовательных тестов: каждый новый вопрос (тест) задается (проводится) в зависимости от предыдущих ответов (от результатов предыдущих тестов). Рассматриваются бинарные тесты (задаются вопросы с ответами «да» или «нет»). Этот процесс можно описать с помощью бинарных деревьев решений. Узлы в таких деревьях соответствуют вопросам (тестам), ветви – исходам теста («да»/«нет» или 1/0). Деревья – строго бинарные. Лист дерева решений соответствует завершению (исходу) поиска (тестирования). В качестве примера можно привести анализ алгоритма бинарного поиска, приведенный в [8, 5.3]. Пусть {1, 2, …, n} – множество исходов поиска. Число шагов поиска (длина теста) есть длина пути li в дереве решений от корня до листа i. Пусть wi – вероятность P(x i) или частота предъявления элемента для поиска, приводящего к исходу поиска i. Тогда M(l) = i=1..n wi li есть математическое ожидание времени поиска (среднее число шагов поиска или последовательного теста). Итак, задача поиска формулируется следующим образом: по заданным n, (i)1n и (wi)1n, где wi = P(x i), построить стратегию поиска (дерево решений), минимизирующую математическое ожидание числа шагов поиска M(l) = i=1..n wi li.
Задача слияния множества упорядоченных списков. Заданы n упорядоченных списков S1, S2, …, Sn. Пусть i 1..n: wi = Si длина списка Si. Требуется построить один упорядоченный список S путем попарного слияния исходных S1, S2, …, Sn и получаемых в процессе этих действий промежуточных упорядоченных списков. Базовая операция слияния двух упорядоченных списков Merge (Si, Sj) требует wi + wj элементарных операций (сравнений и перемещений). Алгоритм Merge (Si, Sj) можно найти, например, в [8, 4.5]. Общее количество операций зависит от порядка попарных слияний. Этот порядок можно задать строго бинарным деревом слияний. Например, дерево
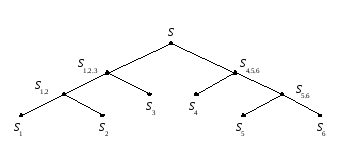
описывает следующую последовательность слияний:
S1, 2 = Merge (S1, S2),
S5, 6 = Merge (S5, S6),
S1, 2, 3 = Merge (S1, 2, S3),
S4, 5, 6 = Merge (S5, 6, S4),
S = Merge (S1, 2, 3, S4, 5, 6).
Легко видеть, что здесь общее количество элементарных операций есть 3w1 + 3w2 + 2w3 + 2w4 + 3w5 + 3w6.
В общем случае совокупное количество элементарных операций есть i=1..n wi li , где li – количество слияний с участием элементов списка Si или, что то же, уровень листа Si в дереве слияний. Требуется построить дерево слияний, структура которого определит оптимальный порядок слияний, а минимальное общее число операций i=1..n wi li будет определяться величинами (li)1n.
1.4. Метод Хаффмана
Элегантное решение (алгоритм) для задачи построения оптимального префиксного кода нашел Д. Хаффман (D. A. Haffman) [18]. Дадим описание этого алгоритма в рекурсивной форме.
Обозначим Wn = (wi)1n. Пусть набор Wn упорядочен:
w1 w2 … wn 1 wn.
Если n = 2, то завершаем процесс кодирования, приписав сообщению с весом w1 код 1, а сообщению с весом w2 – код 0. Иначе (т. е. при n 2) выполняем следующие действия:
-
Из минимальных весов wn 1 и wn образуем
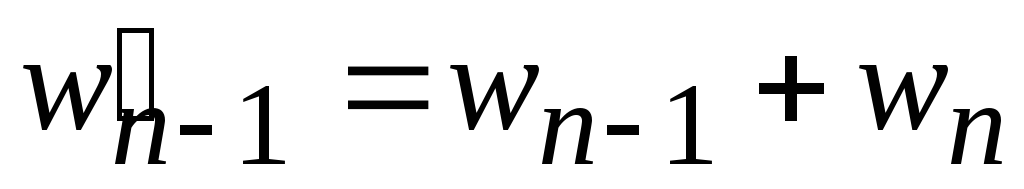 .
. -
Из набора Wn исключаем элементы wn 1 и wn и добавляем в него новый элемент
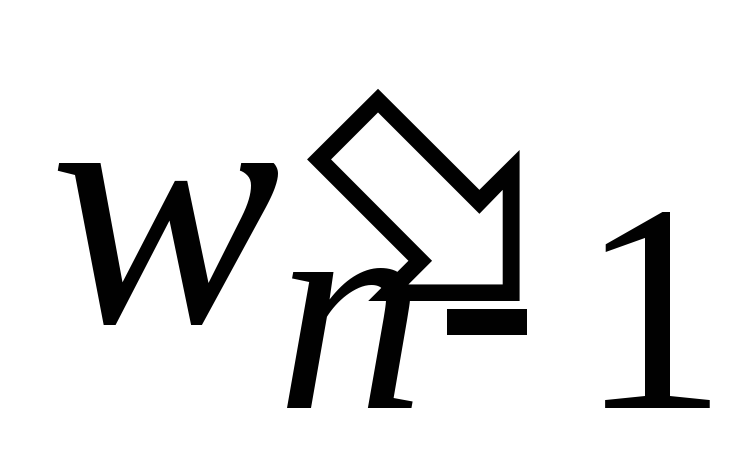 .
Полученный набор обозначим
.
Полученный набор обозначим
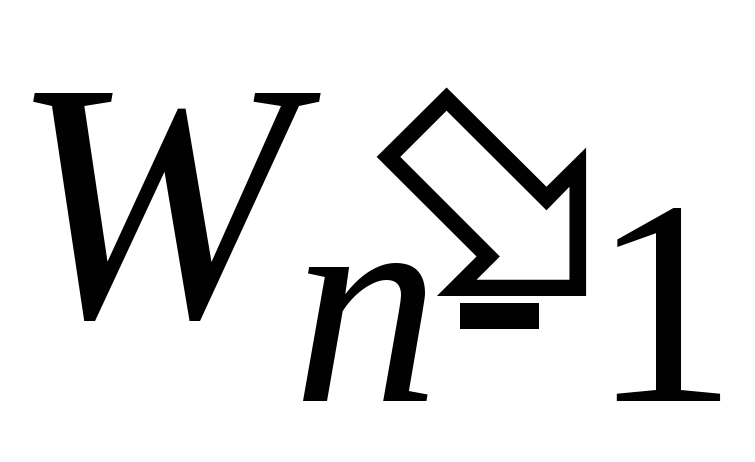 .
. -
Решаем таким же способом задачу с набором весов
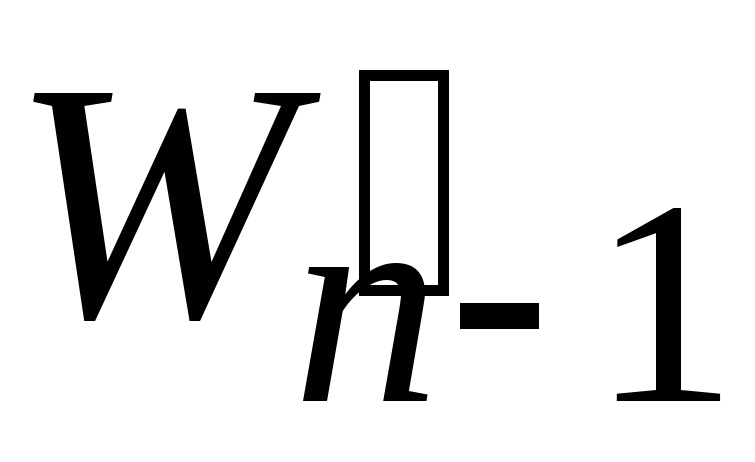 ,
а затем в полученном решении заменяем
узел (лист)
,
а затем в полученном решении заменяем
узел (лист)
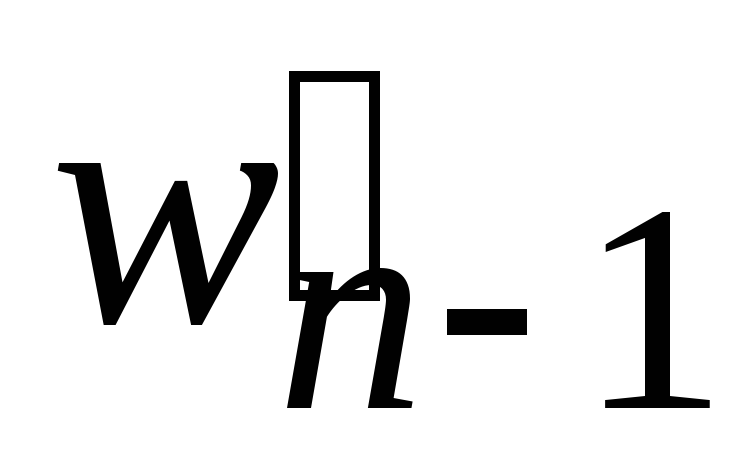 на поддерево из двух листьев wn 1
и wn,
приписав им коды 1 и 0 соответственно.
на поддерево из двух листьев wn 1
и wn,
приписав им коды 1 и 0 соответственно.