Курсовая работа (т): Технологии реплицирования данных
3.
Частичная реплика
Частичной репликой называется база дачных, содержащая ограниченное подмножество записей полной реплики. Распространенным способом создания частичных реплик является использование фильтров, устанавливаемых для конкретных таблиц полной (главной) реплики. Частичные реплики позволяют решить некоторые проблемы, связанные с разграничением доступа к данным и повышают производительность обработки данных. Так, к примеру, в реплику базы данных для определенного подразделения целесообразно реплицировать только те записи таблицы «Сотрудники», которые относятся к данному подразделению, исключив тем самым доступ к другим записям. Техника частичных реплик также снижает затраты на синхронизацию реплик, так как ограничивает количество передаваемых по сети изменений данных.
Возможность включения в реплики объектов базы данных, которые не подлежат репликации, позволяет более гибко и адекватно настроить схему и прочие объекты БД (запросы, формы и отчеты) на специфику предметной области, особенности ввода данных и решаемые информационные задачи по конкретному элементу распределенной системы.
Технологии репликации данных в тех случаях, когда не требуется обеспечивать большие потоки и интенсивность обновляемых в информационной сети данных, являются экономичным решением проблемы создания распределенных информационных систем с элементами централизации по сравнению с использованием дорогостоящих «тяжелых» клиент-серверных систем.
На практике для совместной коллективной обработки данных применяются смешанные технологии, включающие элементы объектного связывания данных, репликаций и клиент-серверных решений. При этом дополнительно к проблеме логического проектирования, т. е. проектирования логической схемы организации данных (таблицы, поля, ключи, связи, ограничения целостности), добавляется не менее сложная проблема транспортно-технологического проектирования информационных потоков, разграничения доступа и т. д. К сожалению, пока не проработаны теоретико-методологические и инструментальные подходы для автоматизации проектирования распределенных информационных систем с учетом факторов как логики, так и информационно-технологической инфраструктуры предметной области.
Тем не менее развитие и все более широкое распространение распределенных
информационных систем, определяемое самой распределенной природой
информационных потоков и технологий, является основной перспективой развития
автоматизированных информационных систем[9].
4. Технологии объектного связывания данных
Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила выработать аналогичные решения и для интеграции разрозненных локальных баз данных под управлением настольных СУБД в сложные децентрализованные гетерогенные распределенные системы. Такой подход получил название объектного связывания данных.
С узкой точки зрения, технология объектного связывания данных решает задачу обеспечения доступа из одной локальной базы, открытой одним пользователем, к данным в другой локальной базе (в другом файле), возможно находящейся на другой вычислительной установке, открытой и эксплуатируемой другим пользователем.
Решение этой задачи основывается на поддержке современными «настольными» СУБД (MS Access, MS FoxPro, dBase и др.) технологии «объектов доступа к данным» - DАО[10].
При этом следует отметить, что под объектом понимается интеграция данных и методов, их обработки в одно целое (объект), на чем основываются объектно-ориентированное программирование и современные объектно-ориентированные операционные среды. Другими словами, СУБД, поддерживающие DАО, получают возможность внедрять и оперировать в локальных базах объектами доступа к данным, физически находящимся в других файлах, возможно на других вычислительных установках и под управлением других СУБД.
Технически технология DАО основана на уже упоминавшемся протоколе ODBC, который принят за стандарт доступа не только к данным на SQL-серверах клиент-серверных систем, но и в качестве стандарта доступа к любым данным под управлением реляционных СУБД.
Непосредственно для доступа к данным на основе протокола ODBC используются специальные программные компоненты, называемые драйверами ODBC (инициализируемые на тех установках, где находятся данные).
Схематично принцип и особенности доступа к внешним базам данных на основе
объектного связывания иллюстрируются на рис. 1.
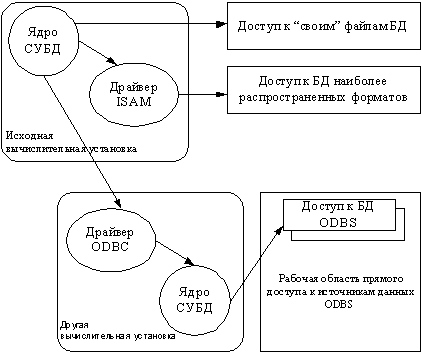
Рис.
1 - Принцип доступа к внешним данным па основе ODBC
Прежде всего, современные настольные СУБД обеспечивают возможность прямого доступа к объектам (таблицам, запросам, формам) внешних баз данных «своих» форматов. Иначе говоря, в открытую в текущем сеансе работы базу данных пользователь имеет возможность вставить специальные ссылки-объекты и оперировать с данными из другой (внешней, т. е. не открываемой специально в данном сеансе) базы данных.
Объекты из внешней базы данных, вставленные в текущую базу данных, называются связанными и, как правило, имеют специальные обозначения для отличия от внутренних объектов. При этом следует подчеркнуть, что сами данные физически в файл (файлы) текущей базы данных не помещаются, а остаются в файлах своих баз данных. В системный каталог текущей базы данных помещаются все необходимые для доступа сведения о связанных объектах - внутреннее имя и внешнее, т. е. истинное имя объекта во внешней базе данных, полный путь к файлу внешней базы и т. П[11].
Связанные объекты для пользователя ничем не отличаются от внутренних объектов. Пользователь может также открывать связанные во внешних базах таблицы данных, осуществлять поиск, изменение, удаление и добавление данных, строить запросы по таким таблицам и т. д. Связанные объекты можно интегрировать в схему внутренней базы данных, т е. устанавливать связи между внутренними и связанными таблицами.
Технически оперирование связанными объектами из внешних баз данных «своего» формата мало отличается от оперирования с данными из текущей базы данных.
Ядро СУБД при обращении к данным связанного объекта по системному каталогу текущей базы данных находит сведения о месте нахождения и других параметрах соответствующего файла (файлов) внешней базы данных и прозрачно (т. е. невидимо для пользователя) открывает этот файл (файлы). Далее обычным порядком организует в оперативной памяти буферизацию страниц внешнего файла данных для непосредственно доступа и манипулирования данными.
Следует также заметить, что на основе возможностей многопользовательского режима работы с файлами данных современных операционных систем, с файлом внешней базы данных, если он находится на другой вычислительной установке, может в тот же момент времени работать и другой пользователь, что и обеспечивает коллективную обработку общих распределенных данных.
Подобный принцип построения распределенных систем при больших объемах данных в связанных таблицах приведет к существенному увеличению трафика сети, так как по сети постоянно передаются даже не наборы данных, а страницы файлов баз данных, что может приводить к пиковым перегрузкам сети. Поэтому представленные схемы локальных баз данных со взаимными связанными объектами нуждаются в дальнейшей тщательной проработке.
Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных и обеспечения ограничений целостности. Совместная работа нескольких пользователей с одними и теми же данными обеспечивается только функциями операционной системы по одновременному доступу к файлу нескольких приложений.
Аналогичным образом обеспечивается доступ к данным, находящимся в базах данных наиболее распространенных форматов других СУБД, таких, например, как базы данных СУБД FoxPro, dBASE[8].
При этом доступ может обеспечиваться как непосредственно ядром СУБД, так и специальными дополнительными драйверами ISAM (Indexed Sequential Access Method), входящими, как правило, в состав комплекта СУБД.
Объектное связывание ограничивается только непосредственно таблицами данных, исключая другие объекты базы данных (запросы, формы, отчеты), реализация и поддержка которых зависят от специфики конкретной СУБД.
Определенной
проблемой технологий объектного связывания является появление «брешей» в
системах защиты данных и разграничения доступа. Вызовы драйверов ODBC для
осуществления процедур доступа к данным помимо пути, имени файлов и требуемых
объектов (таблиц), если соответствующие базы защищены, содержат в открытом виде
пароли доступа, в результате чего может быть проанализирована и раскрыта
система разграничения доступа и защиты данных[12].
5. Технологии удалённого доступа и системы БД,
тиражирование и синхронизация в распределённых системах БД
В технологиях распределенных информационных систем в настоящее время существуют следующие направления:
технологии «Клиент-сервер»;
технологии реплицирования (тиражирования);
технологии объектного связывания.
Распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий.
Технологии и модели «Клиент-сервер».
В основе клиент-серверных технологий лежат две основные идеи:
общие для всех пользователей данные на одном или нескольких серверах;
много пользователей (клиентов) на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные.
Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т.д.).
Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом[13].
В структуре СУБД выделяют три компонента:
компонент представления, реализующий функции ввода и отображения данных;
прикладной компонент, включающий набор запросов, событий, правил, процедур и др. вычислительных функций;
компонент доступа к данным, реализующий функции хранения, извлечения, физического обновления и изменения данных.
Исходя из особенностей реализации и распределения в системе этих компонентов, различают четыре модели технологий «Клиент-сервер»:
модель файлового сервера (FS);
модель удаленного доступа к данным (RDA);
модель сервера базы данных (DBS);
модель сервера приложений (AS).
Модель файлового сервера.
Один
из компьютеров сети определяется файловым сервером (общим хранилищем данных), а
все основные компоненты СУБД размещаются на клиентских установках. При
обращении к данным ядро СУБД обращается с запросами на ввод-вывод данных к
файловой системе. В оперативную память клиентской установки на время сеанса
работы полностью или частично копируется файл базы данных. Достоинствамодели:
простота и отсутствие высоких требований к производительности сервера.
Недостатки: высокий сетевой трафик, отсутствие специальных механизмов СУБД по
обеспечению безопасности данных.
5.1 Модель удаленного доступа к данным
Эта модель основана на учете специфики хранения и физической обработки данных во внешней памяти для реляционных СУБД. В данной модели компонент доступа к данным реализуется в виде самостоятельной программной части СУБД, называемой SQL-сервером, и размещается на сервере. SQL-сервер выполняет низкоуровневые операции по организации, размещению, хранению и манипулированию данными. На сервере размещаются также файлы БД и системный каталог БД. На клиентских установках размещаются программы, реализующие интерфейсные и прикладные функции СУБД. Прикладной компонент клиента формирует необходимые SQL-инструкции и направляет их SQL-серверу, который принимает, интерпретирует, выполняет, проверяет эти инструкции, обеспечивает выполнение ограничений целостности и безопасности данных и направляет клиентам результаты обработки SQL-инструкций (наборы данных).
Достоинства.
В результате реализации такого подхода резко уменьшается загрузка сети. RDA-модель
позволяет также унифицировать интерфейс взаимодействия прикладных компонентов
СУБД с общими данными. Такое взаимодействие стандартизовано в рамках языка SQL
специальным протоколом ODBC, играющим важную роль в обеспечении независимости от
типа СУБД на клиентских установках. Это позволяет интегрировать уже
существующие локальные БД в создаваемые распределенные информационные системы
независимо от типов СУБД клиентов и сервера. Недостатки. Высокие требования к
клиентским вычислительным установкам, так как на них выполняются прикладные
программы обработки данных. Значительный трафик сети, поскольку с сервера
направляются клиентам наборы данных, которые могут иметь существенный объем[14].
5.2 Модель сервера базы данных
На клиентских установках в DBS-модели размещается только интерфейсный компонент, а все остальные компоненты СУБД размещаются на сервере. От клиентов на сервер направляются только вызовы необходимых процедур, запросов и других функций по обработке данных. Все операции по обработке данных выполняются на сервере, а пользователю направляются лишь результаты обработки (а не наборы данных, как в RDA-модели).
Достоинства. Разгрузка сети. Активная роль сервера, что позволяет более эффективно настраивать информационную систему на особенности предметной области, а также более надежно обеспечивать согласованность состояния и изменения данных, что повышает надежность хранения и обработки данных.
Чтобы разнести требования к вычислительным ресурсам сервера в отношении быстродействия и памяти по разным вычислительным установкам, используется модель сервера приложений. Суть данной модели состоит в переносе прикладного компонента СУБД на специализированный в отношении повышенных по быстродействию ресурсов дополнительный сервер системы - сервер приложений. На клиентских установках располагается интерфейсная часть СУБД, откуда вызовы функций обработки данных направляются на сервер приложений. За выполнением низкоуровневых операций по доступу к данным сервер приложений обращается к SQL-серверу, направляя ему вызовы SQL-процедур и получая от него наборы данных. Таким образом, сервер приложений управляет формированием транзакций, которые выполняетSQL-сервер. Поэтому прикладной компонент СУБД, расположенный на сервере приложений, называют монитором транзакций. AS-модель, сохраняя достоинства DBS-модели, позволяет более оптимально построить вычислительную схему информационной системы, однако при этом увеличивается трафик сети.
RDA- и DBS-модели называют двухзвенными (двухуровневыми), AS-модель - трехзвенной (трехуровневой).
На
практике используются смешанные модели, когда простые прикладные функции и
обеспечение ограничений целостности данных поддерживаются процедурами,
хранимыми на сервере, а более сложные функции - бизнес-правила - реализуются
программами, расположенными на клиентских установках или на сервере
приложений[15].