Материал: Программирование учета перевозок в карьере горно-обогатительного комбината
Таблица 1.2
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeDriver |
INTEGER |
|
Р |
|
2 |
Фамилия |
DriverSurname |
VARCHAR |
50 |
|
|
3 |
Имя |
DriverName |
VARCHAR |
50 |
|
|
4 |
Отчество |
DriverPatronymic |
VARCHAR |
50 |
|
|
5 |
Дата рождения |
DriverBirthday |
DATE |
|
|
|
6 |
Паспорт (серия, номер) |
DriverPassport |
VARCHAR |
50 |
|
|
7 |
Адрес |
DriverAdres |
VARCHAR |
300 |
|
|
8 |
Телефон |
DriverPhone |
VARCHAR |
30 |
|
|
9 |
Мобильный телефон |
DriverPhoneMob |
VARCHAR |
30 |
|
|
10 |
Примечание |
DriverComment |
VARCHAR |
1000 |
|
|
11 |
Дата начала работы |
DriverWorkBegin |
DATE |
|
|
|
12 |
Дата окончания работы |
DriverWorkEnd |
DATE |
|
|
Спецификация таблицы tDrivers (Водители)
Таблица 1.3
Спецификация таблицы tCarType (Типы машин)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeCarType |
INTEGER |
|
Р |
|
2 |
Тип |
CarTypeName |
VARCHAR |
50 |
|
|
3 |
Примечание |
CarTypeComment |
VARCHAR |
1000 |
|
Таблица 1.4
Спецификация таблицы tCars (Машины)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeCar |
INTEGER |
|
Р |
|
2 |
Тип |
CodeCarType |
INTEGER |
|
|
|
3 |
Номер (государственный) |
CarNumber |
VARCHAR |
50 |
|
|
4 |
Номер (внутренний) |
CarNumberIn |
VARCHAR |
50 |
|
|
5 |
Модель |
CarModel |
VARCHAR |
50 |
|
|
6 |
Тип |
CarPatronymic |
VARCHAR |
50 |
|
|
7 |
Год выпуска |
CarYear |
INTEGER |
|
|
|
8 |
Дата начала работы в карьере |
CarBegin |
DATE |
|
|
|
9 |
Дата окончания работы в карьере |
CarEnd |
DATE |
|
|
|
10 |
Примечание |
CarComment |
VARCHAR |
1000 |
|
Таблица 1.5
Спецификация таблицы tShift (Смены)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeShift |
INTEGER |
|
Р |
|
2 |
Дата |
ShiftDate |
VARCHAR |
50 |
|
|
3 |
Смена |
ShiftNum |
INTEGER |
|
|
Таблица 1.6
Спецификация таблицы tDriverCar (Водители-машины)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeDriverCar |
INTEGER |
|
P |
|
2 |
Смена |
CodeShift |
INTEGER |
|
|
|
3 |
Машина |
CodeCar |
INTEGER |
|
|
|
4 |
Водитель |
CodeDriver |
INTEGER |
|
|
Таблица 1.7
Спецификация таблицы tUnloading (Пункты разгрузки)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
Код |
CodeUnload |
INTEGER |
|
Р |
|
2 |
Наименование |
UnloadName |
VARCHAR |
100 |
|
|||||
|
3 |
Примечание |
UnloadComment |
VARCHAR |
1000 |
|
Таблица 1.8
Спецификация таблицы tBurdenType (Типы породы)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeBurdenType |
INTEGER |
|
Р |
|
2 |
Тип |
BurdenTypeName |
VARCHAR |
50 |
|
|
3 |
Примечание |
BurdenTypeComment |
VARCHAR |
1000 |
|
Таблица 1.9
Спецификация таблицы tTrip (Рейсы)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeTrip |
INTEGER |
|
Р |
|
2 |
Смена |
CodeShift |
INTEGER |
|
|
|
3 |
Машина |
CodeCar |
INTEGER |
|
|
|
4 |
Пункт погрузки |
TripPPName |
VARCHAR |
50 |
|
|
5 |
Пункт разгрузки |
CodeUnload |
INTEGER |
|
|
|
6 |
Начало движения |
TripTimeBegin |
TIME |
|
|
|
7 |
Окончание движения |
TripTimeEnd |
TIME |
|
|
|
8 |
Простой (мин.) |
TripStanding |
FLOAT |
|
|
|
9 |
Тип породы |
CodeBurdenType |
INTEGER |
|
|
|
10 |
Масса перевозимого груза |
TripMass |
FLOAT |
|
|
|
11 |
Показания счетчика топлива |
TripCounterOil |
FLOAT |
|
|
Таблица 1.10
Спецификация таблицы tCalcOil (Учет топлива)
|
№ п.п. |
Заглавие |
Имя поля |
Тип |
Длина |
Ключ |
|
1 |
Код |
CodeCalcOil |
INTEGER |
|
Р |
|
2 |
Машина |
CodeCar |
INTEGER |
|
|
|
3 |
Смена |
CodeShift |
INTEGER |
|
|
|
4 |
Время |
CalcOilTime |
TIME |
|
|
|
5 |
Показания счетчика |
CalcOilCount |
FLOAT |
|
|
|
6 |
Заправка (л.) |
CalcOilFuel |
FLOAT |
|
|
|
7 |
Примечание |
CalcOilComment |
VARCHAR |
500 |
|
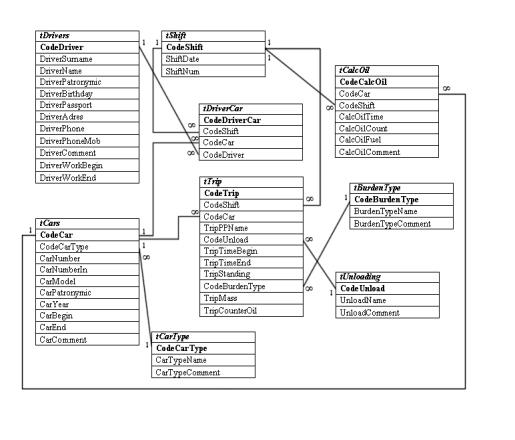
Рис. 1.1. Схема базы данных
1.4
Описание применяемых математических
методов
Поскольку разрабатываемое ПО требует создания базы данных, предоставляющей возможности хранения и защиты информации, то целесообразно рассмотреть здесь понятие базы данных и принципы работы СУБД.
База данных - это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД).
Предметной областью можно назвать мысленно ограниченную область реальной действительности, подлежащую описанию или моделированию и исследованию..
База данных - это единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями из разных подразделений. Вместо разрозненных файлов с избыточными данными, здесь все данные собраны вместе с минимальной долей избыточности. База данных уже не принадлежит какому-либо единственному отделу, а является общим корпоративным ресурсом. Причем база данных хранит не только рабочие данные этой организации, но и их описания. В совокупности, описание данных называется системным каталогом (system catalog), или словарем данных (data-dictionary), а сами элементы описания принято называть метаданными (meta-data), т.е. "данными о данных". Именно наличие самоописания данных в базе данных обеспечивает в ней независимость между программами и данными (program-data independents). И, наконец, следует объяснить последний термин из определения базы данных, а именно понятие "логически связанный". При анализе информационных потребностей организации следует выделить сущности, атрибуты и связи. Сущностью (entity) называется отдельный тип объекта организации (человек, место или вещь, понятие или событие), который нужно представить в базе данных. Атрибутом (attribute) называется свойство, которое описывает некоторую характеристику описываемого объекта; связь (relationship) - это то, что объединяет несколько сущностей. Подобная база данных представляет сущности, атрибуты и логические связи между объектами. Иначе говоря, база данных содержит логически связанные данные.
Архитектура клиент/сервер - это архитектура, которая предусматривает наличие конечного пользователя (клиента), который имеет доступ и возможность обрабатывать данные, сохраняемые на удаленном компьютере - сервере. Сервер предоставляет некоторый сервис, а клиент запрашивает его у сервера. К одному и тому же серверу может обращаться множество клиентов с требованием предоставить им какой-либо сервис, и именно сервер решает, как обработать подобные запросы
Физическое проектирование базы данных - это процесс создания описания реализации базы данных на вторичных запоминающих устройствах с указанием структур хранения и методов доступа, используемых для организации эффективной обработки данных.
Основной целью физического проектирования базы данных является описание способа физической реализации логического проекта базы данных. В случае реляционной модели данных под этим подразумевается следующее:
· создание набора реляционных таблиц и ограничений для них на основе информации, представленной в глобальной логической модели данных;
· определение конкретных структур хранения данных и методов доступа к ним, обеспечивающих оптимальную производительность системы с базой данных;
· разработка средств защиты создаваемой системы.
Проектирование структуры БД предполагает соблюдение правил нормализации (правил Кодда). В случае применения к таблицам с данными каждое правило описывает следующий уровень соответствия требованиям теории реляционных баз данных и различные степени нормализации. Существует пять различных уровней нормализации, но ни одна из реляционных СУБД до сих пор не предоставляет поддержки для всех пяти нормальных форм. Это происходит из-за жестких требований в отношении производительности. Суть дела в том, что в полностью нормализованной базе данных для выполнения запроса вам потребуется соединить столь много таблиц, что производительность такой системы не сможет удовлетворить практических запросов.
Проведение нормализации базы данных состоит в устранении избыточности данных и выявлении функциональной зависимости. Зачем устранять избыточность данных, ясно всем - каждый хотел бы хранить свои наборы данных как можно компактнее, избегая излишнего дублирования. Функциональная зависимость - это термин для обозначения того, что таблица должна быть составлена из данных, которые непосредственно связаны и определяются уникальным идентификатором этой таблицы.
Помимо нормализации к БД применимы такие основные понятия как связи и ключи.
Связь устанавливается между двумя общими полями (столбцами) двух таблиц. Существуют связи с отношением «один-к-одному», «один-ко-многим» и «многие-ко-многим».
Отношения, которые могут существовать между записями двух таблиц:
· один - к - одному, каждой записи из одной таблицы соответствует одна запись в другой таблице;
· один - ко - многим, каждой записи из одной таблицы соответствует несколько записей другой таблице;