Материал: 1_4_ДХафф
Эта страница «сцепляется» с 1.3
1.4. Метод Хаффмана
Элегантное решение (алгоритм) для задачи построения оптимального префиксного кода нашел Д. Хаффман (D. A. Haffman) [18]. Дадим описание этого алгоритма в рекурсивной форме.
Обозначим Wn = (wi)1n. Пусть набор Wn упорядочен:
w1 w2 … wn 1 wn.
Если n = 2, то завершаем процесс кодирования, приписав сообщению с весом w1 код 1, а сообщению с весом w2 – код 0. Иначе (т. е. при n 2) выполняем следующие действия:
-
Из минимальных весов wn 1 и wn образуем
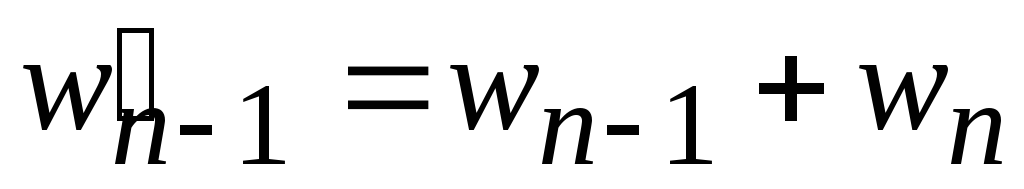 .
. -
Из набора Wn исключаем элементы wn 1 и wn и добавляем в него новый элемент
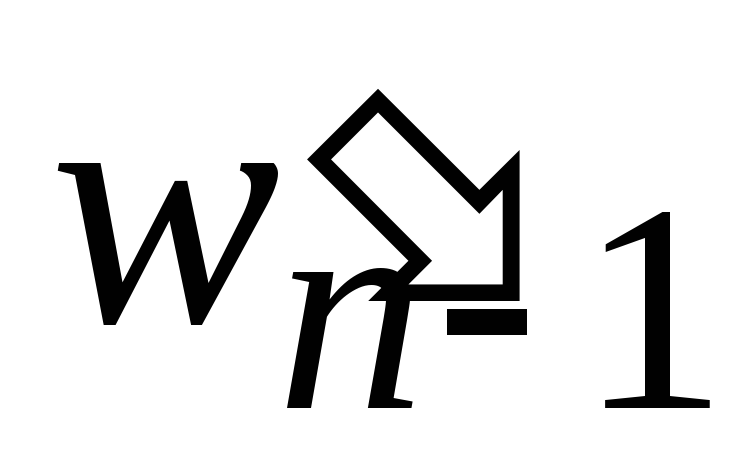 .
Полученный набор обозначим
.
Полученный набор обозначим
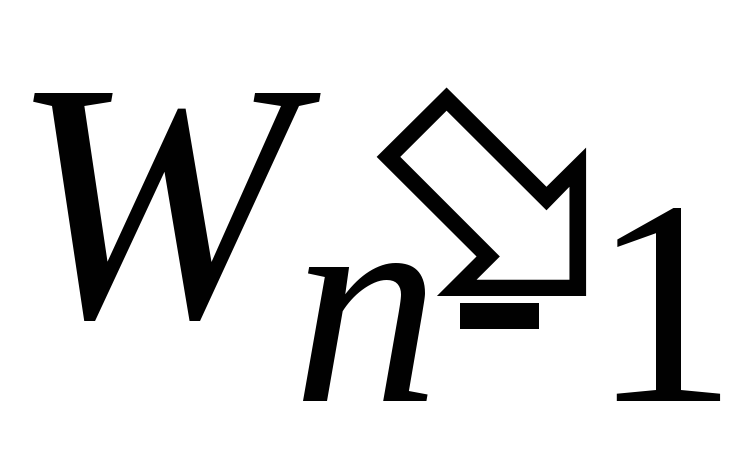 .
. -
Решаем таким же способом задачу с набором весов
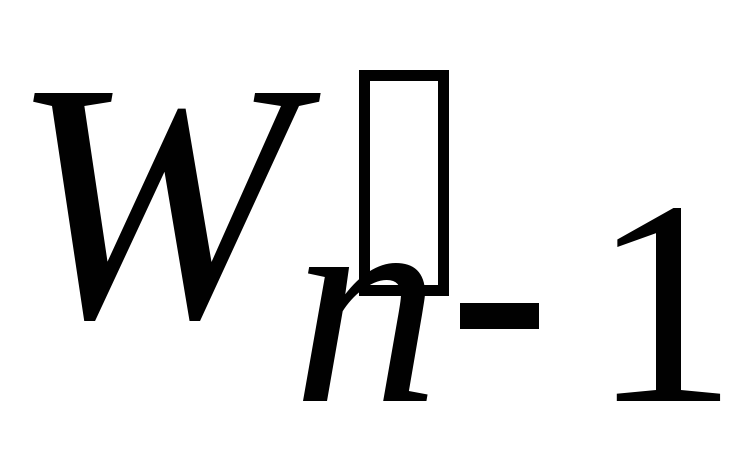 ,
а затем в полученном решении заменяем
узел (лист)
,
а затем в полученном решении заменяем
узел (лист)
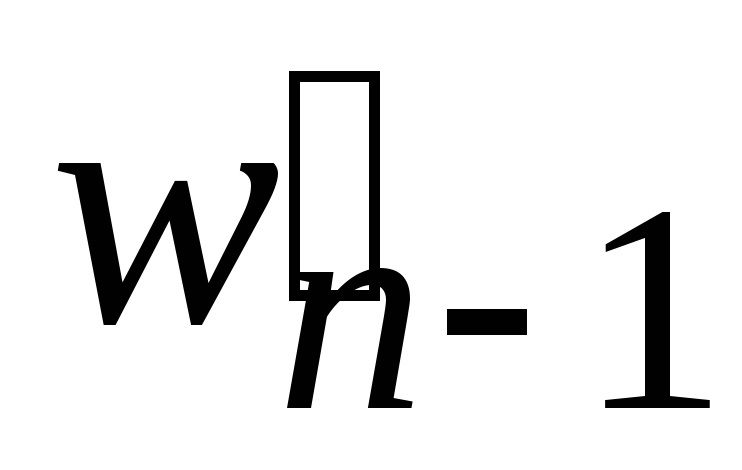 на поддерево из двух листьев wn 1
и wn,
приписав им коды 1 и 0 соответственно.
на поддерево из двух листьев wn 1
и wn,
приписав им коды 1 и 0 соответственно.
Ясно, что набор весов изменится ровно n – 1 раз и алгоритм содержит n – 1 шаг, что легко записать и в итеративном виде (см. 1.5).
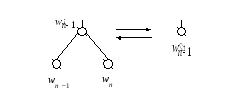
В алгоритме
Хаффмана дерево строится «снизу вверх».
Узлы с наименьшими весами wn 1
и wn
образуют поддерево, которое заменяется
узлом
![]() ,
который в свою очередь далее в нужный
момент участвует в подобном объединении.
Схематично это можно изобразить так:
,
который в свою очередь далее в нужный
момент участвует в подобном объединении.
Схематично это можно изобразить так:
Доказательство оптимальности кода Хаффмана будет дано далее в 1.6.
Пример 1. Пусть дано (тот же пример, что и в 1.1)
|
wi |
3 |
2 |
1 |
1 |
|
i |
А |
Б |
В |
Г |
Работу алгоритма схематично изобразим следующим образом:
3(А), 2(Б), 1(В), 1(Г)
3(А), 2(Б), 2(ВГ)
4(БВГ), 3(А)
7(АБВГ)
З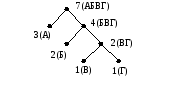 десь
пара объединяемых на данном шаге
«символов» подчеркнута. Результат
замены узлов wn 1
и wn
на узел
десь
пара объединяемых на данном шаге
«символов» подчеркнута. Результат
замены узлов wn 1
и wn
на узел
![]() отображается на следующей строке.
Фактически эта запись представляет в
перевернутом виде дерево
отображается на следующей строке.
Фактически эта запись представляет в
перевернутом виде дерево
Код получился таким же, как и в 1.1.
Пример 2. Пусть дано (тот же пример, что и в 1.2)
|
wi |
8 |
3 |
3 |
3 |
3 |
|
i |
А |
Б |
В |
Г |
Д |
Алгоритм Хаффмана по шагам дает следующее:
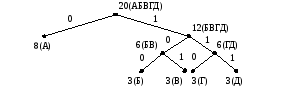
8(А), 3(Б), 3(В), 3(Г), 3(Д)
8(А), 6(ГД), 3(Б), 3(В)
8(А), 6(ГД), 6(БВ)
12(БВГД), 8(А)
20(АБВГД)
Получаем дерево Хаффмана
Полученный код Хаффмана есть
|
wi |
8 |
3 |
3 |
3 |
3 |
|
i |
А |
Б |
В |
Г |
Д |
|
ci |
0 |
100 |
101 |
110 |
111 |
Это тот же код, который приводился в 1.2 как альтернатива коду ФаноШеннона. Для него в 1.2 было получено L = 44 бита, и это оптимальный код.
Пример 3. Пусть дано
|
wi |
6 |
4 |
3 |
2 |
1 |
|
i |
А |
Б |
В |
Г |
Д |
Вариант 1. Алгоритм Хаффмана по шагам дает следующее:
6(А), 4(Б), 3(В), 2(Г), 1(Д)
6(А), 4(Б), 3(В), 3(ГД)
6(А), 6(ВГД), 4(Б)
10(БВГД), 6(А)
16(АБВГД)
Получаем дерево Хаффмана
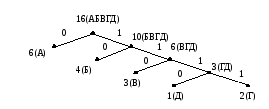
и код
|
wi |
6 |
4 |
3 |
2 |
1 |
|
i |
А |
Б |
В |
Г |
Д |
|
ci |
0 |
10 |
110 |
1111 |
1110 |
Полная длина кода есть L = 61 + 42 + 33 + 4(2 + 1) = 35 бит.
Вариант 2. Отличие на третьем шаге.
6(А), 4(Б), 3(В), 2(Г), 1(Д)
6(А), 4(Б), 3(В), 3(ГД)
6(ВГД), 6(А), 4(Б)
10(АБ), 6(ВГД)
16(АБВГД)
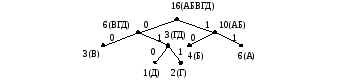 Получаем
другое дерево Хаффмана
Получаем
другое дерево Хаффмана
и код
|
wi |
6 |
4 |
3 |
2 |
1 |
|
i |
А |
Б |
В |
Г |
Д |
|
ci |
11 |
10 |
00 |
011 |
010 |
Полная длина кода есть L = 2(6 + 4 + 3) + 3(2 + 1) = 35 бит.
Сравнивая варианты
1 и 2, видим, что полная длина кода L
в них одинакова, но коды разные. Более
того, максимальная длина кодового слова
для варианта 1 равна 4, а для варианта 2
равна 3. Неоднозначность возникает при
наличии нескольких кандидатов с равным
весом для объединения узлов. Если в
случае равных весов для объединения
узлов в первую очередь использовать
те из них, которые были получены раньше
других (в частности, листья), то, оказывается
[9], что получим дерево (код) с минимальным
значением высоты
(длины кодового слова)
![]() среди всех деревьев (кодов), которые
минимизируют L = i=1..n wi li .
среди всех деревьев (кодов), которые
минимизируют L = i=1..n wi li .
1.5. Реализация алгоритмов кодирования
Рассмотрим реализацию алгоритмов кодирования ФаноШеннона и Хаффмана. Для записи алгоритмов будем использовать псевдокод, основанный на языке Паскаль.
Для представления кодовых деревьев удобно использовать бинарные деревья с размеченными листьями. Эти деревья изоморфны рассмотренным в [1] иерархическим спискам. Их внутренние узлы не содержат иной информации, кроме ссылок на левое и правое поддеревья (деревья строго бинарные), а листья (внешние узлы) содержат собственно элементы базового типа. Рекурсивные типы данных, представляющие такие деревья, используют структуру размеченного объединения (записи с вариантами в языке Паскаль или структуру Union в языках C и C++).
Определим для представления размеченного бинарного дерева типы данных